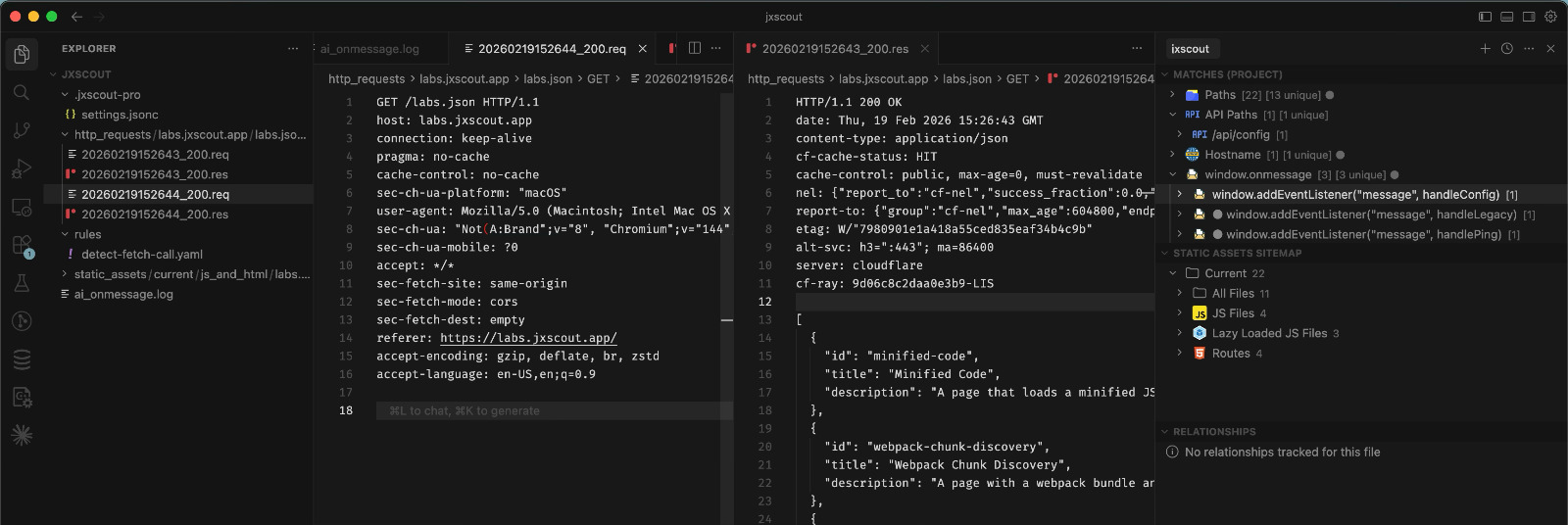
Saving raw HTTP traffic
One of the great benefits of jxscout is that it saves plain files, which tools like Cursor and Claude Code can very easily consume. Because of this, jxscout also has the ability to save plain HTTP request and response data for API requests as files, which can be used by your AI agents to better understand your target.
To avoid bloating your project, jxscout allows you to have a very fine-grained control over the requests that will be saved, and it also allows you to define a maximum number of files that will be saved per endpoint/HTTP verb.
To enable HTTP request ingestion, you should update your project settings like this:
{
// ...
"http_request_ingestion": {
"enabled": true,
"scope": {
"in_scope": [
// You can define multiple entries for in scope,
// and out of scope and jxscout will try to match
// to each one of them before ingesting.
//
// For scope entries all of the fields are optional,
// so you should have a lot of control over what is ingested.
{
"max_saved_requests_per_unique_endpoint": 5,
"request_scope": {
// Only capture requests from the following hosts
"host": ["*jxscout*"],
"path": ["*/api*"],
"method": ["POST"]
}
}
]
}
}
}